Web Scraping

Did you know that web scraping is integral to the data analysis process? It is because it allows quick and efficient extraction of data from different sources, which can then be processed to glean insights as required. Data Analysis is a huge market today, for some of the software giants it’s the source of every decision making, even for small businesses, they get to keep track of the brand value and reputation of their company. You never know when a small automation script to dig in data from various sources might find someplace in engineering life or workspace 😄 (ignore the emoticon, just trying to get your attention).
In this post, I will be using python, it’s a diverse programming language and when you pick the right tools, libraries, you are a superhero. Starting to learn any programming language takes curiosity, will, time, and a couple of energy drinks 😉, I would suggest you getting the basic concept of Python handy if you are not already using it.
Hang on with me for 15 mins and scrape your first website today.
The Basics of web scraping
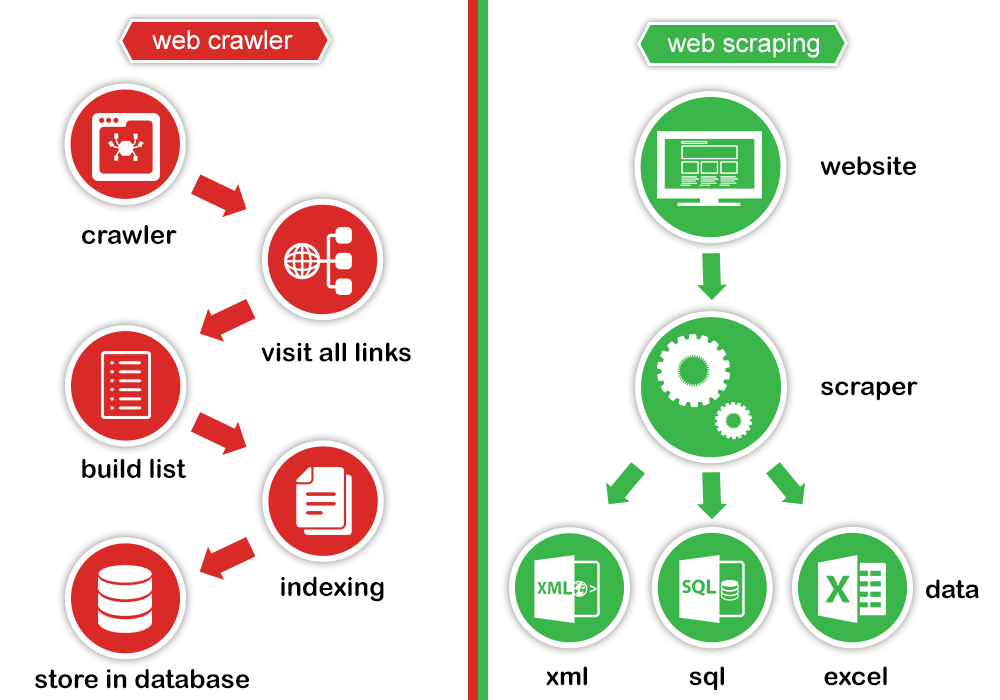
The crawler
A web crawler, which we generally call a “spider,” is an artificial intelligence program that browses the internet to index and searches for content by following links and exploring layers of pages, like a person with too much time on their hands. It’s the machine version of an internet stalker.
The Scrapper
A web scraper is a specialized tool designed to accurately and quickly extract data from a web page. Web scrapers vary widely in design and complexity, depending on the project.
Prerequisite
- An IDE, I prefer Spyder
- Python3, comes pre-installed on Ubuntu, and for another OS, just have it setup. and Test if you can view the Python INteractive Shell by running
python3 - Basic knowledge of HTML tags and python
OK!!! Let’s start
-
Step 1: Import the required libraries we need
- BeautifulSoup from bs4 (It’s a simple library that makes your scraping easy)
- Request and urlopen from urllib
1 2from bs4 import BeautifulSoup from urllib.request import Request, urlopen -
Step 2: Get the Url you want to scrape data from.
|
|
- Step 3: making a request to access resources using the request module
|
|
- Step 4: Creating soup object to parse HTML script
|
|
You can see the beautiful soup object
print(soup.prettify).Which represents the document as a nested data structure
- Step 5: Use a predefined function to extract your desired information.
Open the web page you wanted to scrape, and inspect it using Ctrl+Shift+I key or right-click and select [Inspect]. Now you can see the HTML tags using which you can easily navigate through containers and the data you want to extract.
Here are some simple ways to navigate the HTML with soup
-
soup.titlereturns the title of the context. -
Another common task is extracting all the text from a page:
soup.get_text() -
soup.areturns the link in the context. -
<a>tags represents links in HTML.soup.find_all('a')functions returns a list of all the links in the soup object.
|
|
You can also call get(‘href’) to get links from the anchor (<a>) tag.
|
|
output
|
|
Final Words
It is very straightforward to extract data using beautiful soup. After which you need to use data structures such as the data frame in the pandas’ library which is a very famous one to store the extracted data in a well-structured way. It’s a simple application of python that you can learn if you are a college fresher and this also gives you some hold on python programming and confidence about how basic the coding world is.
I wrote a web-scrapper sometimes back, to extract information from Naukri( a job portal), which scrapes the Job vacancies listed on Naukri’s website in an excel sheet. After which we worked on analyzing what languages are more in demand.
Here is the link to my github repository
Hope you enjoyed the post!!!